Berkin Bozdoğan
Profesör
- Katılım
- 18 Mayıs 2005
- Mesajlar
- 4,926
- Reaksiyon puanı
- 39
- Puanları
- 0
CellWriter adlı sıfırdan geliştirilen yazılımla Linux altında çok daha başarılı el yazısı tanıma seçenekleri oluşabilir. Hem de telif veya patent sınırlamaları olmadan.
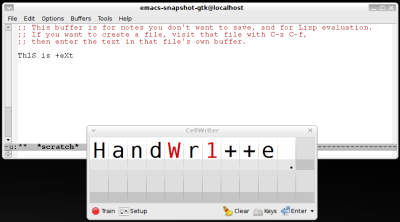
CellWriter, Linux altında çalışan bir el yazısı tanıma hizmeti olarak tasarlanmış ve şu anda gelişim süreci devam ediyor. CellWriter, Michael Levin adlı yazılımcı tarafından geliştiriliyor ve kendisi önceden de el yazısı tanıma konusunda çalışamar vermiş birisi. Daha önceki OneStroke çalışmasındaki kodları tamamen yenileyerek bu projeye girişen Levin, daha başarılı ve fikri mülkiyet sorunlarından uzak bir yazı tanıma sistemi geliştirmeyi hedefliyor.

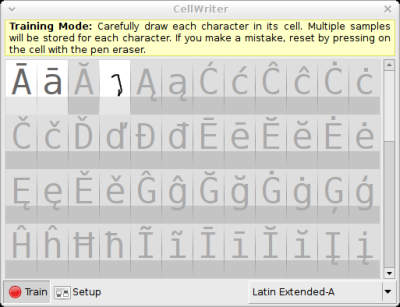
Şu ana kadar Linux altında çalışan el ayzısı tanıma sistemleri ya kapalı kodlu ve sahipli yazılımlar durumunda ya da açık kütüphanelere kapalı veya telif hakllarıyla korunan kütüphanelerin ve eklentilerin eklenmesiyle oluşturulmuş sistemler. Dolayısıyla kamuya açık şekilde üretilmiş bir yazılım gelişime daha fazla hız katacaktır.
Bilgi için: Linux.com
SDN - http.//shiftdelete.net
CellWriter, Linux altında çalışan bir el yazısı tanıma hizmeti olarak tasarlanmış ve şu anda gelişim süreci devam ediyor. CellWriter, Michael Levin adlı yazılımcı tarafından geliştiriliyor ve kendisi önceden de el yazısı tanıma konusunda çalışamar vermiş birisi. Daha önceki OneStroke çalışmasındaki kodları tamamen yenileyerek bu projeye girişen Levin, daha başarılı ve fikri mülkiyet sorunlarından uzak bir yazı tanıma sistemi geliştirmeyi hedefliyor.
Şu ana kadar Linux altında çalışan el ayzısı tanıma sistemleri ya kapalı kodlu ve sahipli yazılımlar durumunda ya da açık kütüphanelere kapalı veya telif hakllarıyla korunan kütüphanelerin ve eklentilerin eklenmesiyle oluşturulmuş sistemler. Dolayısıyla kamuya açık şekilde üretilmiş bir yazılım gelişime daha fazla hız katacaktır.
Bilgi için: Linux.com
SDN - http.//shiftdelete.net
")